I am currently a 2nd-year Ph.D. student at NYU Courant, advised by Prof. Saining Xie. My research interests lie at the intersection of computer vision and multimodal learning, with a particular focus on representation learning, world modeling, spatial intelligence, and long-context modeling.
Publications
(* indicates equal contribution). For full publication list, please refer to my Google Scholar page.
Cambrian-S: Towards Spatial Supersensing in Video
ICLR 2026
Shusheng Yang*, Jihan Yang*, Pinzhi Huang, Ellis Brown, Zihao Yang, Yue Yu, Shengbang Tong, Zihan Zheng, Yifan Xu, Muhan Wang, Daohan Lu, Rob Fergus, Yann LeCun, Li Fei-Fei, Saining Xie
Benchmark Designers Should 'Train on the Test Set' to Expose Exploitable Non-Visual Shortcuts
COLM 2026
Ellis Brown, Jihan Yang, Shusheng Yang, Rob Fergus, Saining Xie
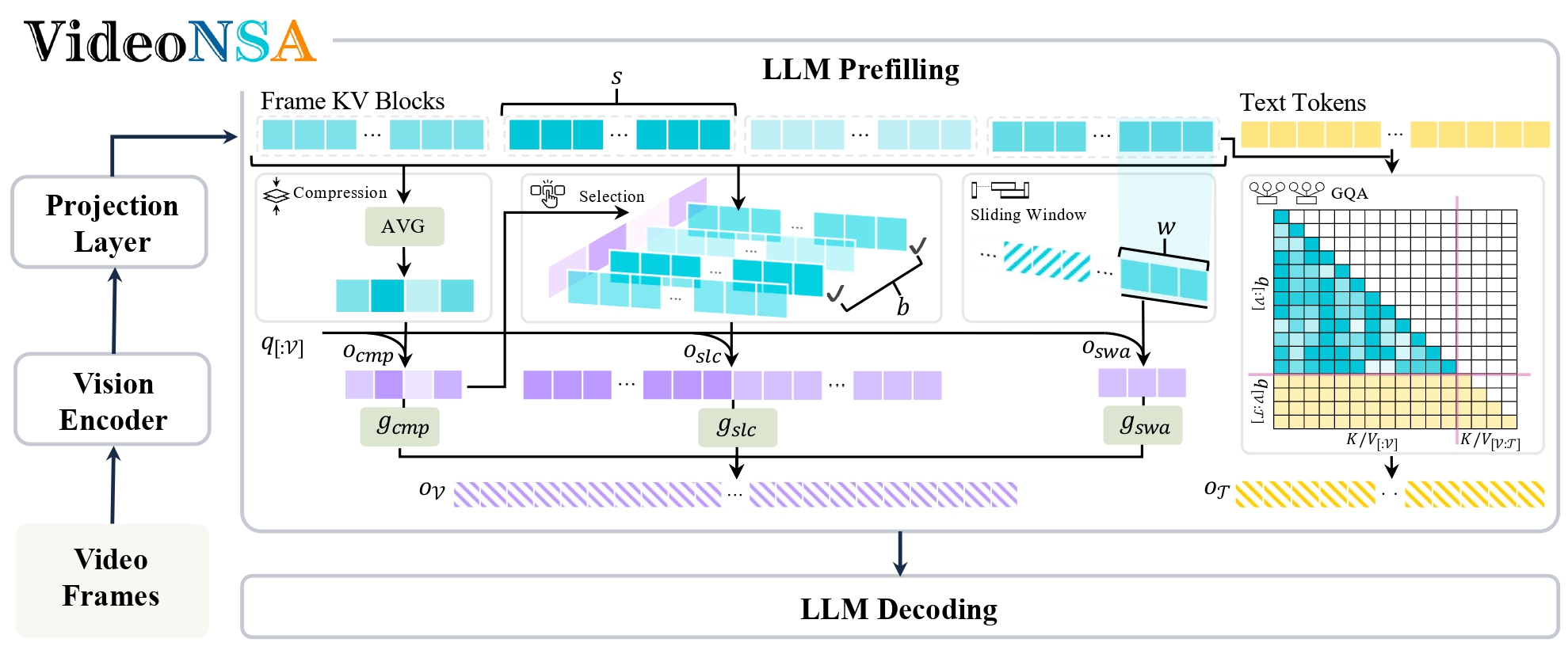
VideoNSA: Native Sparse Attention Scales Video Understanding
ICLR 2026
Enxin Song, Wenhao Chai, Shusheng Yang, Ethan Armand, Xiaojun Shan, Haiyang Xu, Jianwen Xie, Zhuowen Tu
Thinking in Space: How Multimodal Large Language Models See, Remember, and Recall Spaces
CVPR 2025 (Oral)
Jihan Yang*, Shusheng Yang*, Anjali W. Gupta*, Rilyn Han*, Li Fei-Fei, Saining Xie
Cambrian-1: A Fully Open, Vision-Centric Exploration of Multimodal LLMs
NeurIPS 2024 (Oral)
Shengbang Tong*, Ellis Brown*, Penghao Wu*, Sanghyun Woo, Manoj Middepogu, Sai Charitha Akula, Jihan Yang, Shusheng Yang, Adithya Iyer, Xichen Pan, Ziteng Wang, Rob Fergus, Yann LeCun, Saining Xie
Qwen-vl: A frontier large vision-language model with versatile abilities
Tech Report
Jinze Bai*, Shuai Bai*, Shusheng Yang*, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, Jingren Zhou
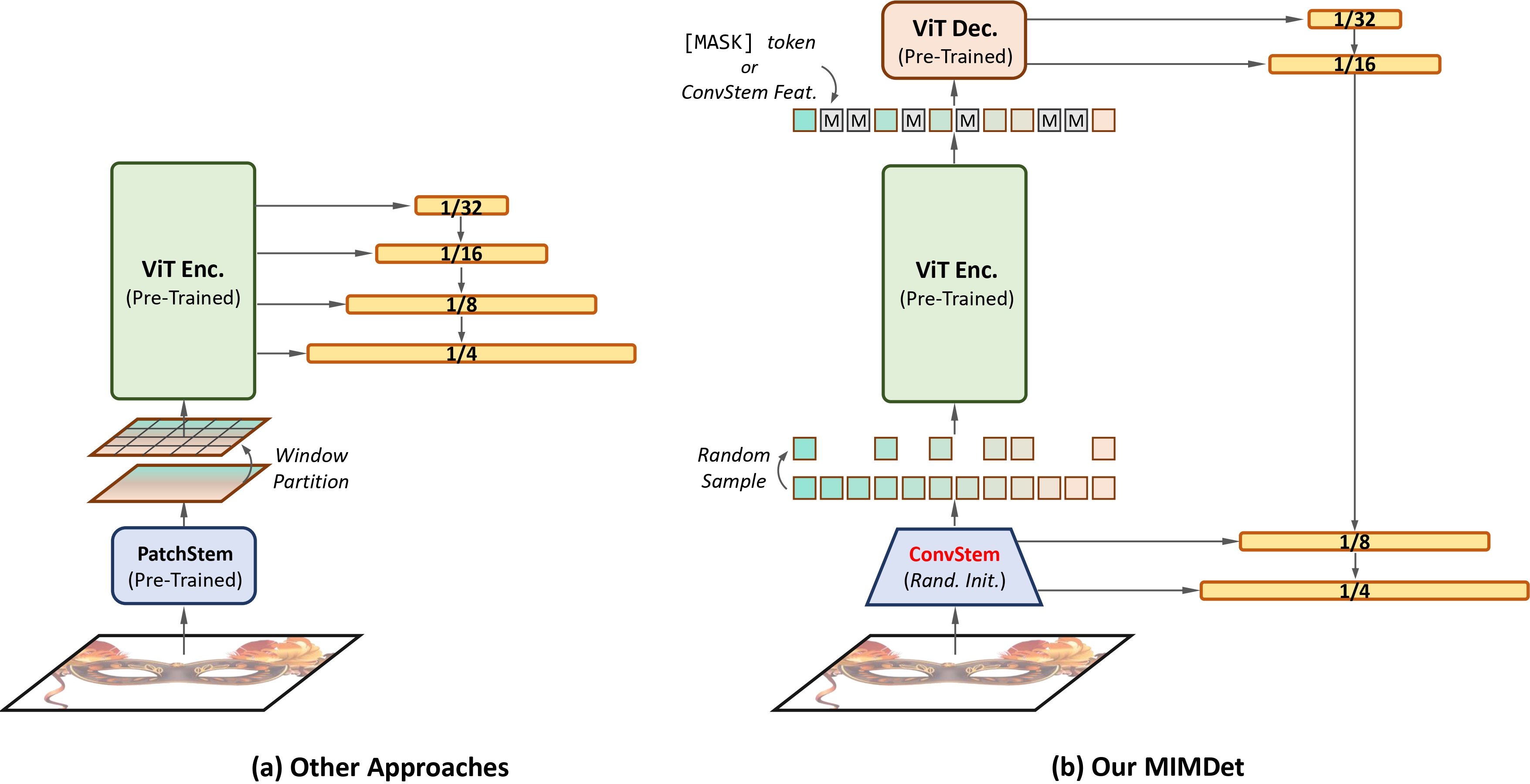
Unleashing Vanilla Vision Transformer with Masked Image Modeling for Object Detection
ICCV 2023
Yuxin Fang*, Shusheng Yang*, Shijie Wang*, Yixiao Ge, Ying Shan, Xinggang Wang
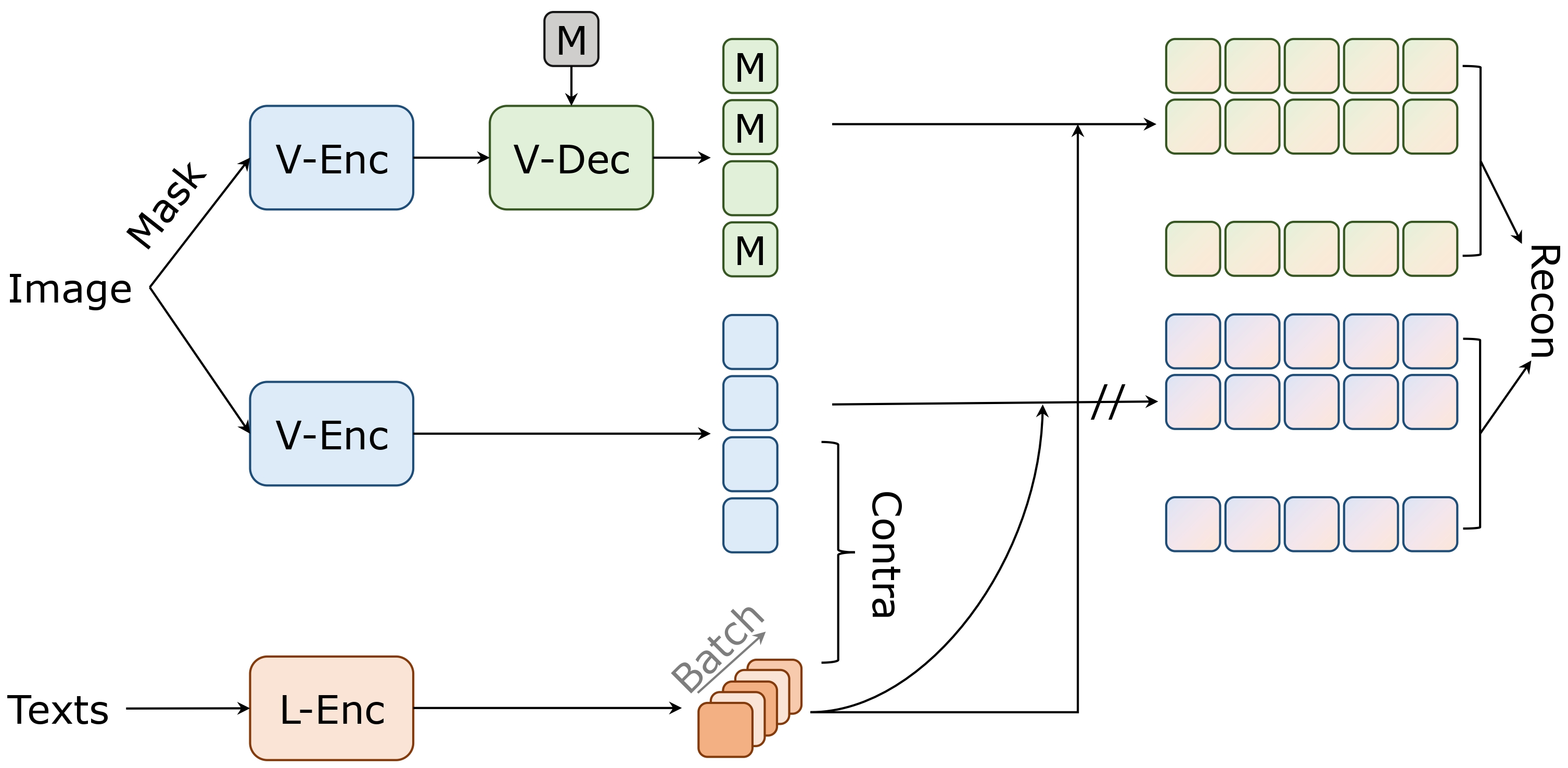
Masked Visual Reconstruction in Language Semantic Space
CVPR 2023
Shusheng Yang, Yixiao Ge, Kun Yi, Dian Li, Ying Shan, Xiaohu Qie, Xinggang Wang
Temporally Efficient Vision Transformer for Video Instance Segmentation
CVPR 2022 (Oral)
Shusheng Yang, Xinggang Wang, Yu Li, Yuxin Fang, Jiemin Fang, Wenyu Liu, Xun Zhao, Ying Shan
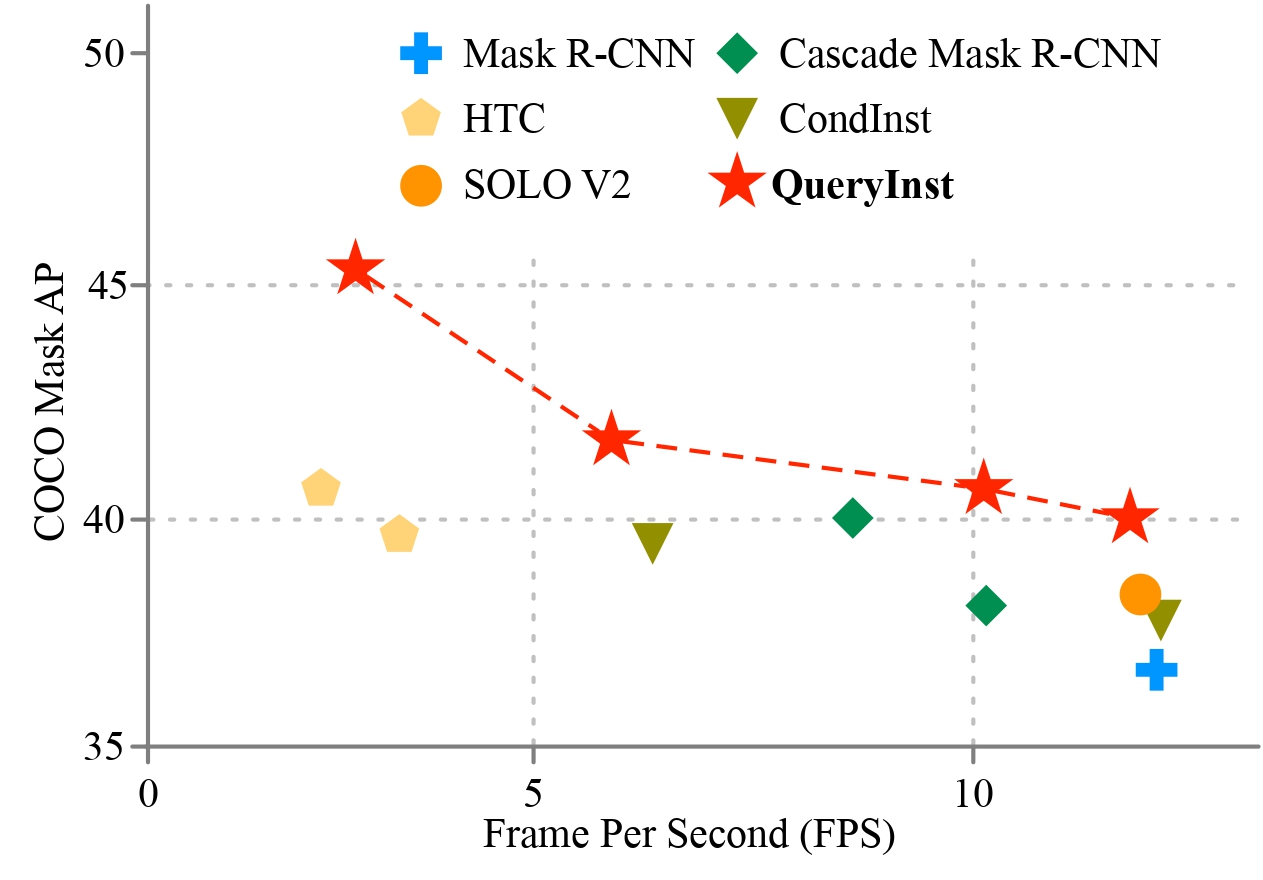
Instances as queries
ICCV 2021 & CVPRW 2021
Yuxin Fang*, Shusheng Yang*, Xinggang Wang, Yu Li, Chen Fang, Ying Shan, Bin Feng, Wenyu Liu
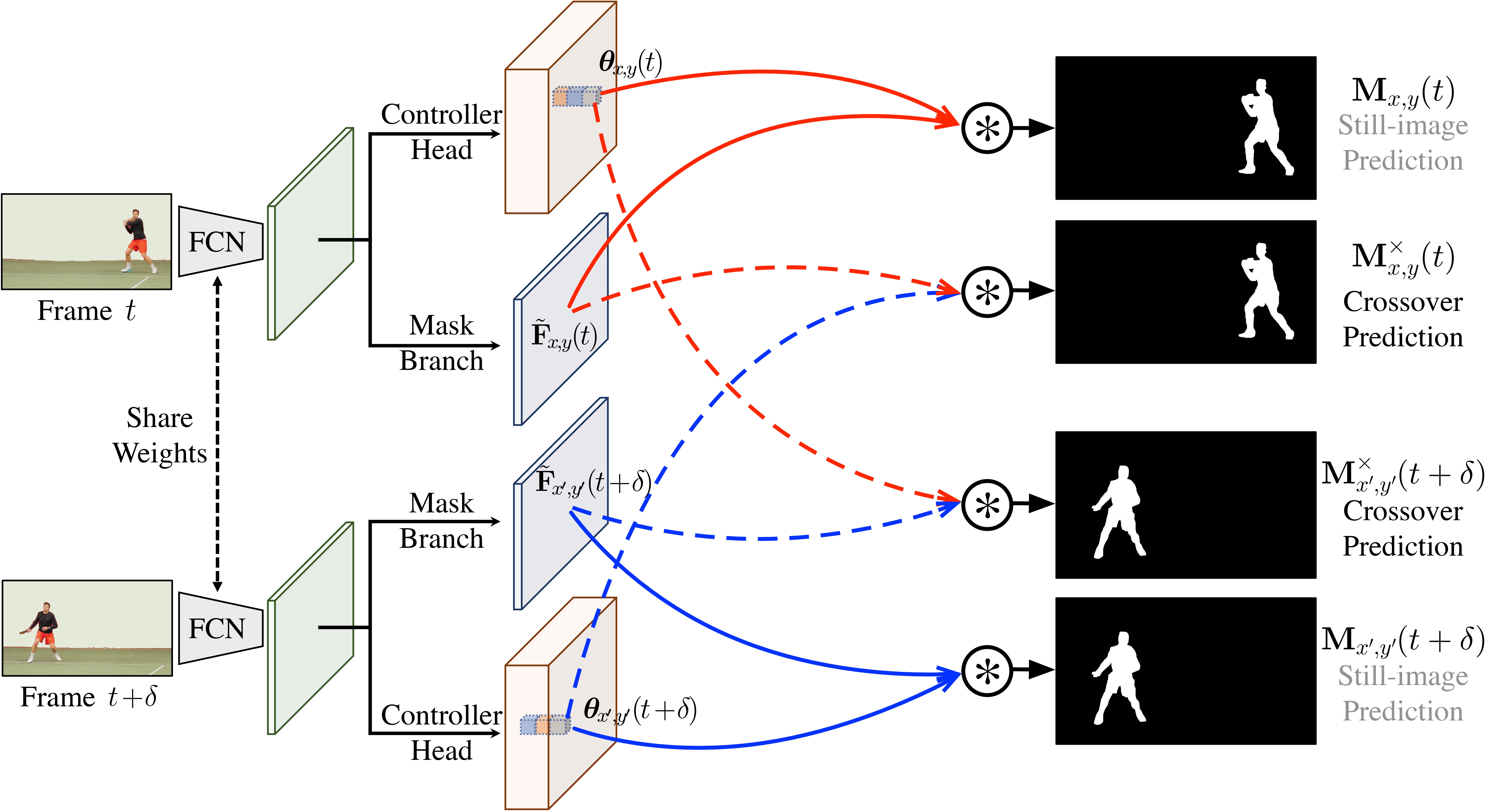
Crossover learning for fast online video instance segmentation
ICCV 2021
Shusheng Yang*, Yuxin Fang*, Xinggang Wang, Yu Li, Chen Fang, Ying Shan, Bin Feng, Wenyu Liu